TL;DR
Web video is becoming a powerful foundation for robot learning, but the current frontier articles do not describe autonomy as a web-video-only problem. Rhoda AI uses web-scale video pretraining to make robot policies more data-efficient, but its Direct Video-Action model still depends on long robot video context, proprioception, embodiment data, inverse dynamics, task robot data, and streaming closed-loop execution [2]. Genesis AI frames manipulation as a full-stack system problem, where data, hardware, sensing, control, simulation, and evaluation have to scale together [1].
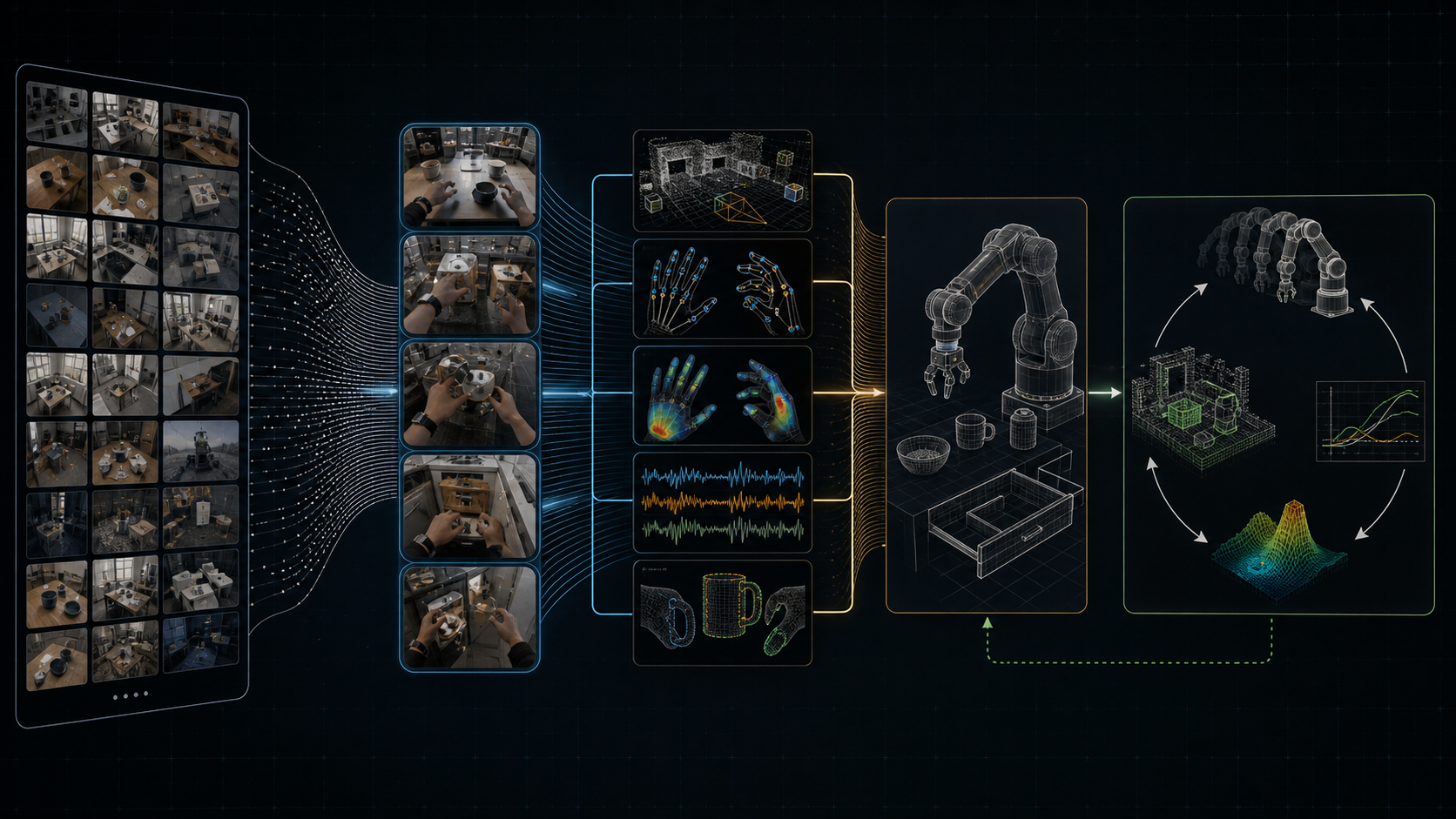
The shared requirement is more precise than "more robot demos" or "more web video." Robot autonomy needs human-centric physical data: natural task behavior, egocentric and third-person video, hand state, tactile/contact signals where manipulation requires them, robot embodiment data, actions or controls, and closed-loop feedback.
Why this is a data problem
Robotic manipulation is not only perception. It is contact, timing, force, memory, state estimation, control, and recovery from error. Genesis states this directly: navigation can often avoid contact, while manipulation is the problem of composing contact in space and time [1].
That is why the data requirement cannot stop at ordinary visual observation. A robot has to learn what is happening, what matters, what action should come next, and how the world changes after the action. A video of a human task may show motion and scene context, but it can miss hand state, contact quality, force, pressure, slip, robot embodiment constraints, and the controls that would make the behavior executable on a machine.
Web video is the starting point, not the whole stack
Rhoda makes the strongest case for web video as a robotics foundation. Its article calls web video the most scalable data source for the dynamic physical world and argues that video generation is an effective objective for learning physical knowledge for robot decision-making [2].
Its Direct Video-Action model reformulates robot control as video generation: a causal video model predicts future video, and an inverse dynamics model translates that predicted future into robot actions [2]. At runtime, the model is conditioned on a long history of robot video, proprioception, and other conditioning signals such as language [2].
The frontier lesson is not that web video removes robot data. Rhoda reports data efficiency, including inverse-dynamics training with about 10 hours of data from an embodiment type, and task examples using 11 hours and 17 hours of robot data [2]. The stronger claim is that a video-first architecture can make robot data more efficient when the rest of the system preserves the signals needed to translate prediction into action.
Genesis: human-centric data as a scaling path
Genesis approaches the same bottleneck from a different direction. Its GENE-26.5 article describes capable manipulation as a system problem rather than a pure model problem. The system spans sensors, actuators, control, data, and the model [1].
The key phrase is not just "human data." Genesis describes a human-centric data engine and says collection has to preserve the work it comes from: if data collection changes behavior, it limits both scale and fidelity [1].
Genesis organizes its scalable data engine around three complementary sources [1]:
- Glove data for high-fidelity hand motion and tactile signals.
- Egocentric video for natural behavior and real-world task diversity.
- Third-person video for broad coverage of physical interaction.
Those sources sit on a quality-quantity frontier. Egocentric and third-person video scale naturally, but video alone may lose action-relevant state. Glove data is richer for hand motion and contact, but it requires instrumentation. The frontier requirement is therefore a balanced stack, not a single modality.
What human-centric means
It preserves natural task behavior.
Genesis emphasizes that data must be captured without interrupting the work it comes from [1]. If the collection method changes how people act, the model may learn the collection setup instead of the task.
It exposes action-relevant state.
Egocentric video can capture what the actor sees. Third-person video can capture external geometry and object motion. But dexterous manipulation often depends on hidden state: finger pose, contact patch, pressure distribution, slip, grip transitions, and forceful interaction. Genesis' glove direction is a direct response to this gap [1].
It connects observation to action.
Rhoda's architecture separates future-video prediction from inverse dynamics. The video model predicts what should happen next; the inverse dynamics model converts the predicted video into robot actions [2].
It supports closed-loop evaluation.
Robotics is not evaluated only by whether a prediction looks plausible. The robot's actions change future observations. Genesis emphasizes closed-loop performance and scalable evaluation [1]. Rhoda likewise uses a streaming loop where prediction, action, and observation repeat continuously [2].
Contact-rich manipulation raises the bar
The difference between video understanding and robot manipulation becomes sharp at contact. In Rhoda's task examples, the robot has to handle long-horizon industrial behaviors such as unpacking, sorting, decanting, latch handling, container breakdown, unexpected object positions, strong force, partial observability, and correction after mistakes [2].
Genesis points in the same direction. Its examples emphasize dexterous, contact-rich manipulation across long-horizon tasks, and its model stack spans language, vision, proprioception, tactile sensing, and action [1]. For manipulation, pixels are necessary but not sufficient. Useful data has to carry state across vision, body, contact, action, and feedback.
What this means for robot autonomy
The current frontier requirement is not "more data" in the abstract. It is more data with the right structure.
- What was visible over time?
- What was the human or robot trying to do?
- What did the hand, tool, object, and scene state look like?
- Where did contact happen?
- What action or control changed the scene?
- What did the system observe after acting?
- Did the behavior succeed, fail, recover, or need correction?
Web video can help models learn broad physical priors. Human-centric data helps connect those priors to real tasks. Robot embodiment data makes the behavior executable. Closed-loop feedback determines whether the robot system actually works.
That is the data required for robot autonomy: not just more pixels, and not only robot demonstrations, but synchronized empirical traces that carry human skill toward robot action.
References
-
[1]
Genesis AI, "GENE-26.5: Advancing Robotic Manipulation to Human Level," Genesis AI Blog, May 2026. genesis.ai/blog/gene-26-5-advancing-robotic-manipulation-to-human-level
-
[2]
Rhoda AI, "Causal Video Models Are Data-Efficient Robot Policy Learners," Rhoda AI Research, March 2026. rhoda.ai/research/direct-video-action
Argus-Ego-1
Sample discussions
For teams evaluating human-worn egocentric capture as part of their data stack, Argus-Ego-1 is available for sample-device discussions.